Pwnablekr_Toddlers Bottle_memcpy
SSH로 접속하면 c파일과 readme 파일이 있다. readme 파일에서는 9022포트에 접속하라고 한다.

코드에서는 일정 범위의 숫자를 입력 받고, 실험을 한다. memcpy를 입력받은 크기만큼(입력한 바이트만큼) 하는 실험이며, 입력과 실험을 10번 시행한다. slow_memcpy와 fast_memcpy의 성능을 비교하기 위한 실험을 하는 것으로 보인다.
int main(void){
setvbuf(stdout, 0, _IONBF, 0);
setvbuf(stdin, 0, _IOLBF, 0);
printf("Hey, I have a boring assignment for CS class.. :(\n");
printf("The assignment is simple.\n");
printf("-----------------------------------------------------\n");
printf("- What is the best implementation of memcpy? -\n");
printf("- 1. implement your own slow/fast version of memcpy -\n");
printf("- 2. compare them with various size of data -\n");
printf("- 3. conclude your experiment and submit report -\n");
printf("-----------------------------------------------------\n");
printf("This time, just help me out with my experiment and get flag\n");
printf("No fancy hacking, I promise :D\n");
unsigned long long t1, t2;
int e;
char* src;
char* dest;
unsigned int low, high;
unsigned int size;
// allocate memory
char* cache1 = mmap(0, 0x4000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
char* cache2 = mmap(0, 0x4000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
src = mmap(0, 0x2000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
size_t sizes[10];
int i=0;
// setup experiment parameters
for(e=4; e<14; e++){ // 2^13 = 8K
low = pow(2,e-1);
high = pow(2,e);
printf("specify the memcpy amount between %d ~ %d : ", low, high);
scanf("%d", &size);
if( size < low || size > high ){
printf("don't mess with the experiment.\n");
exit(0);
}
sizes[i++] = size;
}
sleep(1);
printf("ok, lets run the experiment with your configuration\n");
sleep(1);
// run experiment
for(i=0; i<10; i++){
size = sizes[i];
printf("experiment %d : memcpy with buffer size %d\n", i+1, size);
dest = malloc( size );
memcpy(cache1, cache2, 0x4000); // to eliminate cache effect
t1 = rdtsc();
slow_memcpy(dest, src, size); // byte-to-byte memcpy
t2 = rdtsc();
printf("ellapsed CPU cycles for slow_memcpy : %llu\n", t2-t1);
memcpy(cache1, cache2, 0x4000); // to eliminate cache effect
t1 = rdtsc();
fast_memcpy(dest, src, size); // block-to-block memcpy
t2 = rdtsc();
printf("ellapsed CPU cycles for fast_memcpy : %llu\n", t2-t1);
printf("\n");
}
printf("thanks for helping my experiment!\n");
printf("flag : ----- erased in this source code -----\n");
return 0;
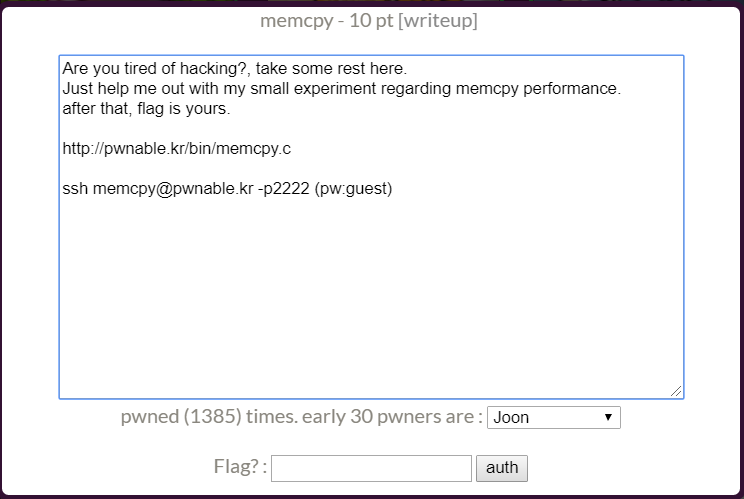
}하지만 값을 넣고 실행해보면 중간에 프로그램이 터져서 종료된다. 아래는 직접 c파일을 컴파일한 후 실행한 모습이다. 5번째 실험에서 세그멘테이션 폴트가 나서 프로그램이 종료된다. 그래서 플래그를 출력해주지 않는다.
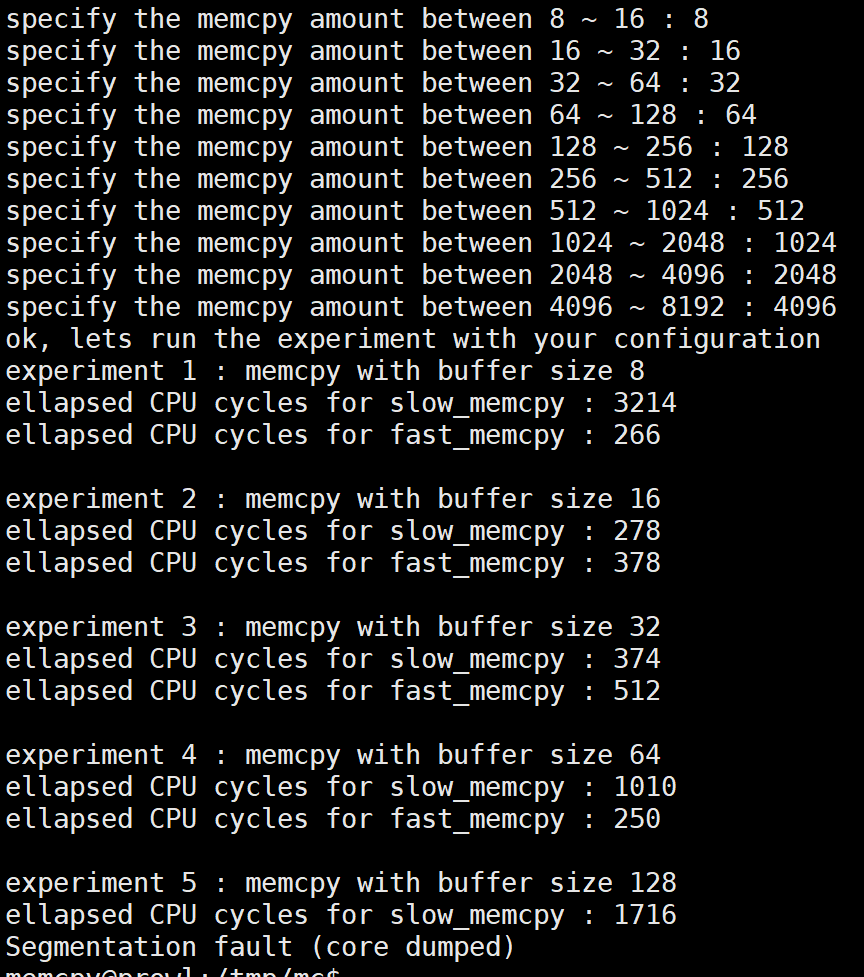
입력 숫자를 크게 하면 조금 더 빨리, 4번째에서 터진다.
버퍼 사이즈가 128 이상일 때 문제가 생긴다고 예상한다. fast_memcpy에서 에러가 났으니 이 함수를 살펴본다.
char* fast_memcpy(char* dest, const char* src, size_t len){
size_t i;
// 64-byte block fast copy
if(len >= 64){
i = len / 64;
len &= (64-1);
while(i-- > 0){
__asm__ __volatile__ (
"movdqa (%0), xmm1\n"
"movdqa 32(%0), xmm3\n"
"movntps xmm1, 16(%1)\n"
"movntps xmm3, 48(%1)\n"
::"r"(src),"r"(dest):"memory");
dest += 64;
src += 64;
}
}
// byte-to-byte slow copy
if(len) slow_memcpy(dest, src, len);
return dest;
}남은 양이 64보다 클 경우 xmm 레지스터를 이용하여 복사한다. xmm 레지스터는 한 번에 16바이트를 올릴 수 있다.
이렇게 4개의 xmm 레지스터를 이용하여, 한 루프에서 64바이트 단위씩 복사한다. 남은 양이 64보다 작으면 slow_memcpy를 이용하여 처리한다.
core파일을 이용하여 어디서 에러가 발생했는지 찾아보았다.
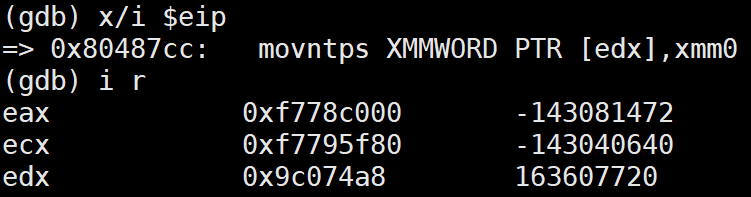
어셈블리어로 짠 부분에서, 복사한 데이터를 목적지에 저장하는 코드에서 에러가 발생한다. movntps 명령어는 16바이트 단위로 정렬된 주소를 요구하는데, malloc의 결과로 얻은 주소가 정렬되어 있지 않기 때문에 에러가 발생했다.

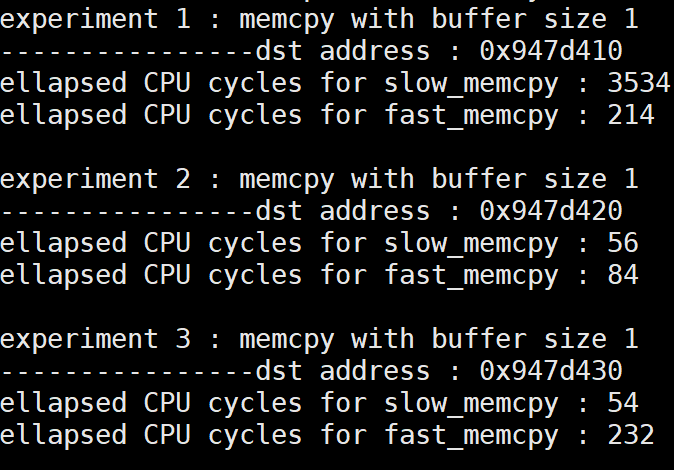
코드를 수정하여 입력값 한계를 없앤 뒤 1 바이트씩 할당해 보았다. malloc chunk 헤더와 푸터 8바이트를 포함하여 16바이트씩 사용된다. 즉, 데이터는 헤더 푸터를 제외한 8바이트 alignment로 할당된다고 추정할 수 있다.
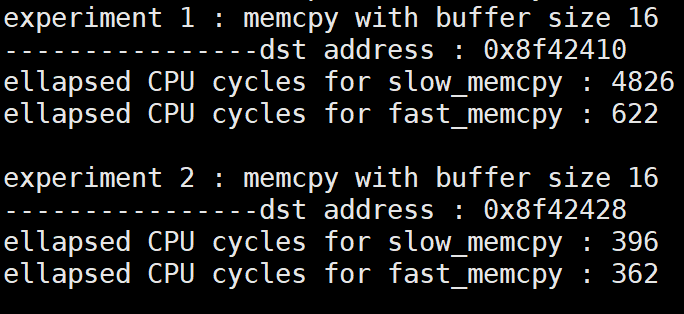
할당 크기가 64보다 작은 시점에서는 slow_memcpy를 하기에 alignment를 맞추지 않아도 괜찮다.
이를 고려하여 적절한 크기를 생각해보자. 시작 주소가 16바이트 alignment를 맞추기 위해서는, malloc chunk 헤더, 푸터를 포함한 크기가 16의 배수인 편이 좋다.
헤더, 푸터를 합치면 8바이트이므로 할당하는 데이터의 크기는 8의 배수이면서 16의 배수는 아니어야 한다.(헤더, 푸터까지 합쳐서 할당된 메모리가 16배수이어야 하기에) 딱 떨어지지 않더라도 8바이트 alignment를 맞춰주겠지만, 계산의 편의를 위해서 8의 배수이게 했다.
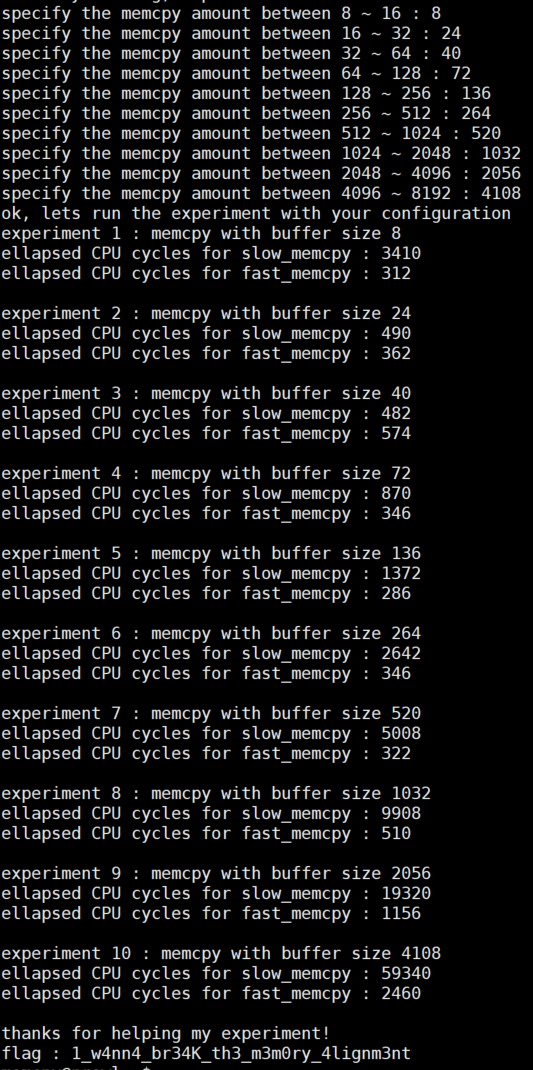
위 규칙을 지키며 입력값을 주면 flag를 출력한다.
flag는 1_w4nn4_br34K_th3_m3m0ry_4lignm3nt 이다.
tags: writeup, pwnable, elf file, linux, c lang, x86asm, memory alignment